作为一名digital marketer, 西西莉亚一直对Facebook广告背后的运作机制非常感兴趣。
网上可以查找到很多关于Facebook广告竞价的算法的文章,却因为未被公开,很少有关于广告投放中推荐受众的算法的讨论。
西西莉亚之前做过机器学习的课题,再加上对AdTech的一些小小的心得和研究,决定自己动手丰衣足食,亲自上阵写一写Facebook广告背后的故事。?
这是一篇关于Facebook广告(推荐受众)算法的技术分析贴。目的在于和大家探讨一下,机器学习和人工智能在算法中的作用,揭开“黑盒”机制的神秘面纱。
西西莉亚会尽量讲的通俗一些,而且只挑选对广告投手们比较有用的部分。太细节太深度的内容,我们还是留给学术界吧。
1 社交网络与人工智能
首先,Cecilia觉得有必要简单的区分下“人工智能(AI)”和“机器学习(Machine Learning)”两个概念。人工智能最近火的不行,它其实是一个比较宽泛的名词,指的是所有可以用计算机模仿人类的行为并且代替人类执行人工作业。
机器学习是人工智能的实践和应用,具体是通过大数据来训练算法和数据模型,从而更加准确地对新的(未知)数据及指令作出预测和判断。再往下走,又会是深度学习(Deep Learning)等,作为广告投手不需要知道那么学术和专业的东西。
本文中西西莉亚主要用的名词“机器学习”,但是大家要知道人工智能和机器学习某些情况下其实指的是一回事。人工智能的概念其实很早就被提出来了,大家还记得经典电影《黑客帝国》吗?电影中就讲到人类和智商卓越的机器之间的斗争。
但是为什么近几年才大火?
因为人工智能需要依靠数据驱动,而早前的计算机是没有办法高速处理海量数据信息的。
直到硬件产业的瓶颈被突破,海量数据并行处理的CPU甚至更强大的GPU面世,AI终于可以摆脱束缚,尽情地汲取所有可以获得的信息,发展一日千里。
所以可以简单粗暴的说,没有数据,就没有人工智能。
那么,数据从哪里来?
除了专业的研究数据采集,对于像Facebook这样的社交网络,每天有上亿的用户自发地生成各种数据(UGC):照片、影片、语音、文字、社交互动等等。除此之外,Facebook还可以通过你的浏览器的cookie来追踪你在互联网上的一切行为。比如你浏览过哪些网站?你搜索过哪些内容?你产生过哪些购买行为?
在Facebook的官网中有这样一段话:
“ We use cookies to help us show ads and to make recommendations for businesses and other organizations to people who may be interested in the products, services or causes they promote.”
所以,Facebook主要是通过追踪浏览器的cookie来收集用户的数据,进而对用户的喜好和行为进行预测,选择最适合的广告呈现在用户面前。
同时Facebook又用cookie来判断控制广告的投放,以及评估广告的质量。
比如确保该广告出现在同一个用户的时间线上不超过X次(impression)。再比如该用户是否与广告产生了交互行为(点击、留言、点赞、购买。。。等等)。
作为互联网时代的小尖兵,又稳坐社交网络头把交椅,Facebook拥有这个世界上最值钱的数据:全世界超过20亿的活跃用户信息。
但凡走过,必留下痕迹。
你在互联网上的一切行为都被转换成计算机可以读懂的数据,进而为之所用。
2 机器学习算法在广告受众推荐上的应用
Facebook ad算法是预测性算法(Predictive Algorithm)。
简单的说,机器学习的算法通过“学习”广告投放得到的反馈(历史数据),对新的广告投放效果进行预测。
机器学习算法的两大类别:回归算法(Regression)和分类算法(classification)。
回归算法的结果是一些连续的值,比如一元二次方程里的一条直线,任意一个横坐标的X值,都可以找到一个对应的Y值。而分类算法的输出结果并不是连续的,而更像是一段又一段的区间。
举个例子?,当你问“这个用户看到广告后会不会点击购买我的产品”?
通过分析,分类算法会告诉你,“Yes”还是“No”。
但是回归算法会告诉你“只有68.59%的可能性会买,也有31.41%的可能性不会买”。
实际上,两种算法并不是完全无法不兼容彼此的。
比如你在回归算法的输出层规定区间,“低于60%的值输出No”,“不低于60%的输出值为Yes”,这样回归算法就转化为一个分类算法了。
不管使用哪种算法,在广告投放领域,机器学习的核心都是通过分析audience的特性(demographics),来对TA的行为进行预测。
用户的每一个特性都是一个“自变量X”,而模型的输出值,也就是“因变量Y”。
在回归模型中,一个拟合的方程可以写为:
Y = a*X1 + b*X2 - c*X3 +d*X4。。。
其中的X1/X2/X3/X4。。。可能代表的含义是:
- 性别、
- 年龄、
- 地址、
- 是否为Engaged shopper、
- 热爱时尚、
- 喜欢小狗、
- 家里有刚出生的宝宝、
- 喜欢的颜色、
- 喜欢的音乐类型。。。
而a/b/-c/d。。。就是一些常量参数,影响每个自变量的权重,也可以理解为,对因变量Y的影响程度高低。
因变量Y就代表你的广告的目标(objective)。
当你选择购买的时候,Y可能就代表这个用户是否会转化产生购买行为。当你选择的目标是“视频观看(Video View)”时,Y就代表广告推送给的这个人会不会耐心地看完你的广告。
因为Facebook广告的算法对外界仍然是非公开的,是个黑盒(Black Box)。所以两种算法其实都有可能,甚至可能是两种算法的结合。
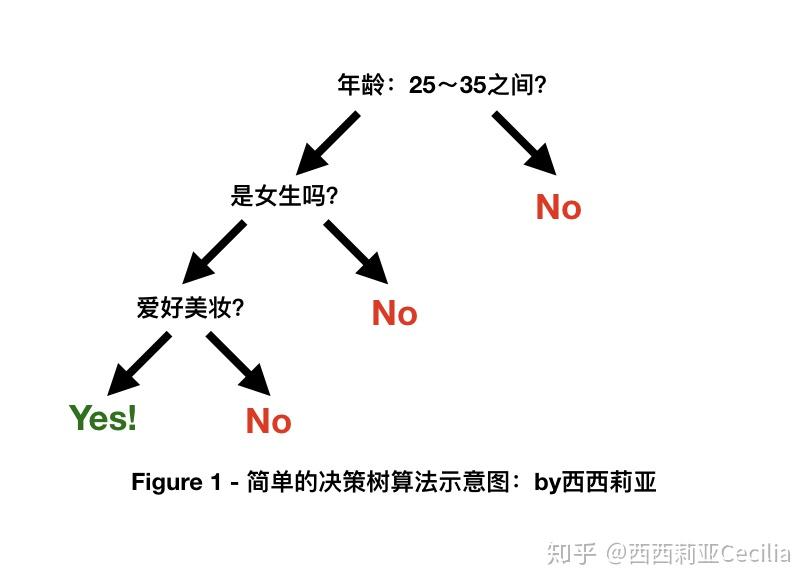
分类算法最简单的就是“决策树(Decision Tree)”。
决策树是我认为最直观的一种机器学习算法。最简单的决策树是“二元决策树”,即对每一个问题的回答只有两个答案:“Yes”或者是“No”。
比如通过训练,Facebook ads的算法发现,年龄在25~35岁、性别为“女”、爱好为“美妆和时尚”的受众最容易对你的广告产生转化。
于是在此之后,对每一个新的“潜在受众”,Facebook广告算法都会问:
“
- 这个人的年龄是在25到35之间吗?不是 -> PASS。是 -> 进入下一题。
- 这个人是女的吗?不是 -> PASS。是 -> 继续下一题。
- 这个人有跟”美妆时尚相关的爱好吗?“ 不是 -> PASS。是 -> 好哒!就是你了!美女,这里有个广告你要不要了解一些?
”
接下来,灵魂画手西西莉亚就用几张直(超)观(丑)的图来解释一下这几个算法:
而回归算法就略微复杂一些。
最简单、也是最基础的算法就是线形回归(Linear Regression)。
假设我们只有一个自变量X,表示用户的年龄。
因变量Y就是我们的广告投放的目标(Objective),比如说“购买”的可能性(概率)。
这个模型简单粗暴,通过一个用户的年龄来决定TA的购买行为。
根据广告的投放经验,我们得到一些离散的点,每个点可以被描述为(年龄,是否会购买),比如(25,Yes),(65,No), (30,Yes) 。
最后得到的曲线可能看起来像下面这张图:
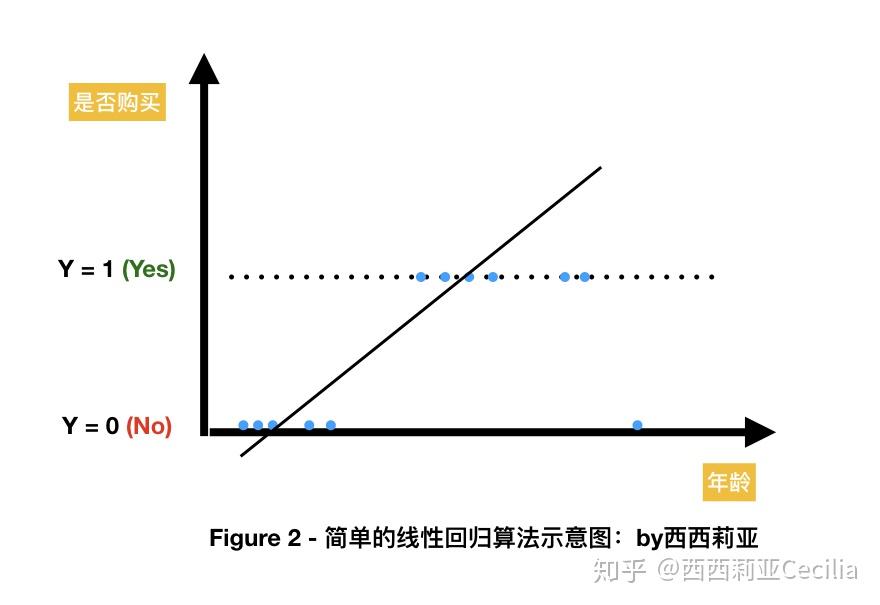
为了方便,我们把“Yes”和“No”都转化为“1”和“0”。
【PS:其实这个例子不太好啦,因为因变量Y只有两个值0和1,算是比较特例。
真实生活中Y往往也是个连续的值,比如观看视频的时常,或者消费的金额。】
这个例子里,我们得到一个简单的一元一次方程。
比如算法发现,年龄越大,钱越多,购买力越强。
所以就会使劲儿把你的广告尽可能的推送给上了年纪的人。
但是在现实生活中呢,我们的Target Audience的属性才不会这么简单只有年龄一个。
想想我们之前举例说的那些X1/X2/X3/X4/X5。。。
每一个兴趣,都在某一个维度上描述了某一个受众。
比如,(“张三”,“男”,“30岁”,“单身”,“爱好撸猫”。。。)。
如果只有”年龄“一个维度,算法的拟合结果就给我们一条二维空间的”直线“。
而如果加上“性别”,我们有了2个自变量,算法就会给我们一个三维空间里的”面“。
再加上“感情状况”,我们就有了3个自变量,算法就会给我们一个四维空间里的“体”。
至于五维、六维、七维。。。就是一些无法描述的“形状”了。
每一个受众,在算法的世界里,都是一个被拆解为多维向量代表的“点”。
而机器学习,就是寻找在这浩瀚的空间中、无数个散落的点之间的联系和规律。
算法的最终结果,就是一条划过这个“多维宇宙”的、能穿起数量最多的“星星”的一条“线”。
这条“线”,就是机器学习的拟合(Fitting)结果。
【PS: 其实在多维空间上,这已经不是一条“线”了。大家可以想象为投影在二维的坐标轴上的一条线比较容易理解。】
当机器学习得到稳定的拟合结果后,对于每一个新的受众,算法就会通过对TA的特征进行分析,然后得到一个这个“点”距离预测的“线”之间的距离。
如果距离为零,代表这个受众完美符合我们的所有条件,非常有可能转化,Facebook ads的算法就会把广告推送到他面前。
距离越远,代表这个受众越不可能转化。算法于是自动跳过他而不会投放给他广告。
Facebook广告的Learning Phase就是在不断的训练算法模型,寻找完美的拟合曲线。一旦学习结束,算法就会寻找目标受众中,距离曲线最近的点(潜在受众)。
3 数据!数据!!数据!!!
不管是分类算法,还是回归算法,要想让算法训练出最精准的模型,最重要的就是需要足够的数据。
a/b/-c/d。。。是这个模型中的参数,它们一开始都没有固定的值,是在算法收集到足够的数据后才会推算出来他们的数值。
当你开始推送广告之后,Facebook的算法还没有任何数据(或者是它的数据库里的有限的自有数据),它只是试探着,在你选择的target audience里面随机地推送广告。
一旦某个用户有了相应的反馈,比如给广告点赞、或者点击了购买链接,Facebook会将该用户的数据收集入你的数据库里。
如果我们只有零散的几个数据,得到的拟合结果也会比较简单,甚至会产生过拟合(overfitting)。
简单说就是很容易被一些特例的数据影响,而无法准确找到更加通用的拟合曲线。
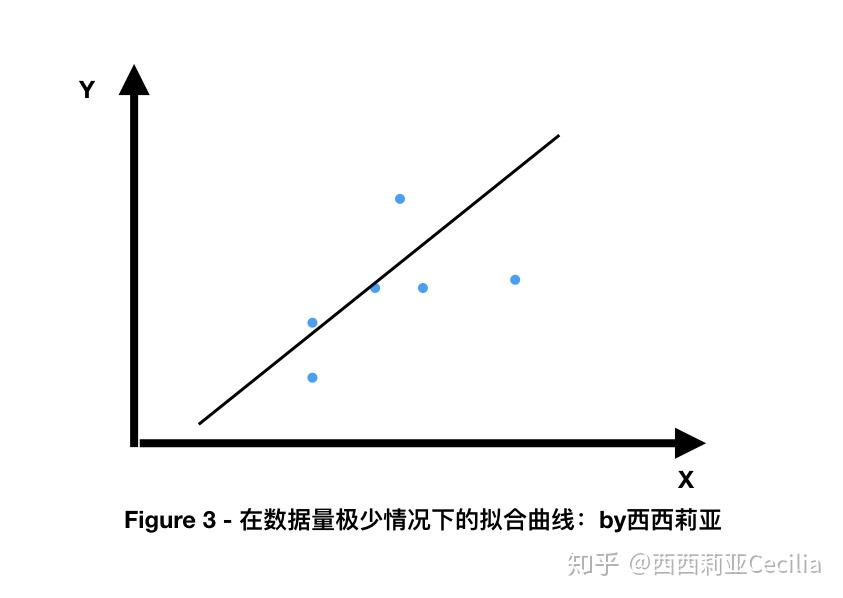
数据越多,越容易找到这些离散的点之间的相似性,从而对新的数据进行更加准确的预测。
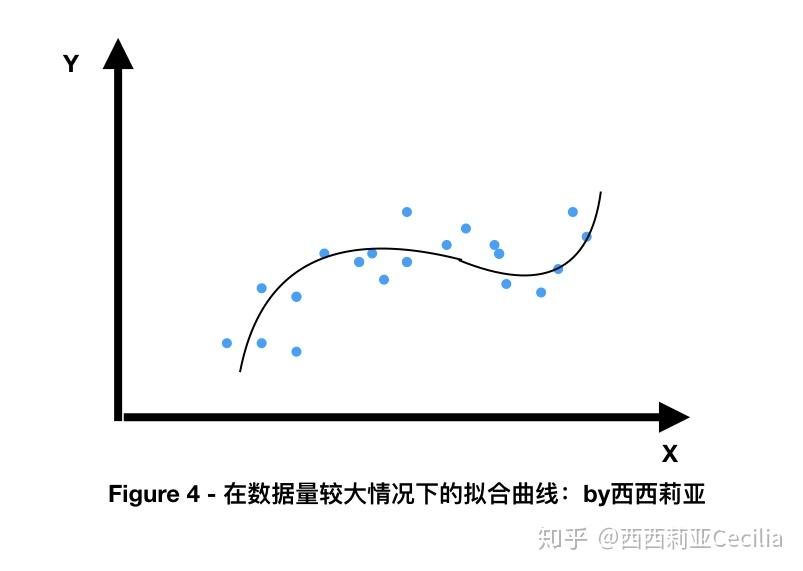
所以,聪明的童鞋们四不四已经恍(早)然(知)大(如)悟(此),如果我们得到的数据足够多(花的钱足够多),我们就会得到大量在多维宇宙里如群星般散落的点。
这个时候会不会有人说,你说的不是废话嘛?谁不知道广告就是要多花钱。
《奇葩说》有一期黄执中在辩论中讲到:
“真实的世界,是由一连串随机、混沌、细小的决策,以及漫长的因果链所组成的。一只蝴蝶煽动翅膀,可以在远方引起风暴。”
我想说,在广告届这个理论也是成立的。
在广告主最初选择的一个target audience之后,Facebook Ads的算法其实是随机的开始选择初始受众。
在得到一个最初的模型之后,算法会尝试着寻找和这些用户有相似特性的其他用户、并且推送相同的广告来反复确认自己的判断。
如果结果不符合预期,算法就会调整策略,比如调整某个特性的权重。
在这个调整的过程中,有可能会影响到广告主的决策。
比如你的完美受众可能是20~25岁的女生,但是你一开始并没有对年龄做任何的限制,而Facebook根据它已有的数据可能就“猜测”35~40岁的受众比较理想。
结果跑了几天,广告效果很差,没有耐心的人有可能就此打住,终止广告。
其实你再坚持一下,就可以“看到明天的太阳了”。。。啊不对。。是算法可能就找到更理想的受众了。
因为随机性,导致决策的变化,从而影响整个数字营销的效果。
数据不会说谎,但是片面的数据,会误导我们的判断能力。
接下来,西西莉亚就和大家讨论一下,如何降低这些偶然性和不确定性。
4 所以。。。我们应该?
说了这么多,到底要怎么做,才可以避免被一些算法的不确定性影响广告投放的效果呢?
西西莉亚在这里列几点,是我目前能想到的、也是最容易做到的、广告投手可以注意到的事项:
4.1 - 保证足够的budget
我们已经知道,算法的本质就是寻找数据之间的关联和共性,所以简单来讲,数据越多越好。
但是到底要多少数据才够呢?
很遗憾告诉大家,这并没有一个“定量”。
“大数据”的5V特征包括:大体量(Volume),多样性(Variety),高速度(Velocity),准确性(Veracity)、稀缺性(Value)。
但是到底多“大”才能被称为大数据,学术界并没有统一的定义。
同理,到底多少广告数据才够,也只能见仁见智了。
Facebook官方文档说,至少25~50次转化才建议优化。这应该是差不多训练算法需要的数据的最少要求了。
西西莉亚建议大家量力而行。根据自己的能力决定一个初始预算,制定相应的KPI。
如果广告投放的效果没法达到自己的预期目标,那就调整预算或者KPI。如果一直入不敷出就可以尝试停掉这个campaign,改变广告的素材或者调整受众,重新投放。
不用担心之前投放的钱打了水漂了,你之前花掉的那些钱相当于跟Facebook买了数据。
Facebook会保存数据180天,这意味着180天之内你的数据都可以被算法所用。
4.2 - 加快广告的投放速度
理论上来讲,同一个campaign,如果你的预算是1000刀,那么每天10刀持续投放100天和一天之内全部花掉1000刀买到的数据的数量一样。
实际上,如果算法决定了某个受众是你的广告的完美受众,决定是否投放给TA还需要由很多别的因素决定。
比如广告的Quality Score,又比如竞价(Auction)算法。
高质量的受众和数据谁都想要,当然就是出价高者得咯!
尤其是对于“购买转化”为目标的广告,本来受众的价格平均来说就很高。如果你的出价低于平均水平,Facebook只能帮你找到一些质量比较低的leads。
迟迟得不到转化,相当于就得不到有效的数据,算法就“巧妇难为无米之炊”。
再加上Facebook存储数据有时间限制,西西莉亚建议,与其每天10刀连续投放100天地“挤牙膏”,倒不如一次性地投入1000刀,得到大量优质数据。
之后再用这些买到的数据,进行“再营销(Re-targeting)“和建立“相似受众(Look Like Audience)”,理论上来讲,效果会好得多。
4.3 - 不要频繁地改变投放策略
很多没有耐心的童鞋,广告放出去一两天,看到没有效果就坐不住了,想立刻改素材或者改受众。
可是。。。心急吃不了臭豆腐啊喂!
我了解大家的心情,感觉每一分钟money都在不停地哗哗地往外流,heart疼的要死。
可是作为专业的广告投手,当然要有看的更长远的眼光和能力啦!
你要转化思维,想象这些钱都换成数据哗哗哗地流回到你的帐户里。╮( ̄▽ ̄"")╭
算法也是需要数据才可以训练出稳定的投放模型哪!
特别是一开始,从无到有的积累过程,算法是及其不稳定的(Facebook广告算法的Learning phase)。
要是一有波动就调整策略,很可能会“误杀”有潜力的广告,白白浪费掉一些数据。
所以广告投放也要做好“放长线钓大鱼”的心理准备,通过观察长期的数据曲线变化来做出更实际的预测和更合理的调整。
Facebook广告的算法不断地经过海量数据的洗礼,要对它的智能有信心啊。
4.4 - 获取尽量精准的数据
算法的训练需要数据,可是数据和数据也是不一样的哦!
最简单的例子,对于不同的投放目标(objective), 获取数据的难易程度也是不一样的。
如果只是简单的PPE,Facebook广告算法知道哪些受众最可能和广告产生互动,它自己的数据库里就有需要的数据。
但是如果是购买转化(Purchase Conversion),这些数据只能来自于你的网站。
有很多人说,就算没有任何初始数据,也可以直接投放转化广告。
在之前的文章中,西西莉亚反复提及,Facebook广告的目标是“冲动型消费者”。
所以就算不是同一个business或者产品,冲动型消费者们也会有一些共通的特质。
Facebook可以在你的target audience里找到之前有过购买经验的人,以他们的数据作为训练集。
但是Facebook并不鼓励这样做。
每一个广告和产品都(应该是)独一无二的。
如果你用别的产品的数据来训练另一个产品的推送算法,弊端就是价格贵,数据少、甚至有偏差。
当然如果您是土豪,当我没说。只要能出得起价,总是能买到足够的优质数据的。
类似的问题,还有比如是开一个“杂货铺”还是某一个精准的“niche”的网店。
越是精准的niche,在数据体量相同的条件下,流量纯度会越高,对算法的训练越有利。
比如一个“杂货铺”之前是卖牙齿美白产品,现在又开始卖钓鱼钩,两个完全不搭旮的niche。
就算之前已经有了很多的购买量,但是这些数据可能在训练“鱼钩广告”的模型中就不好使。
但是这些问题也是可以通过对数据分类克服的。
你可以在自己的数据“仓库”里,设置一个“牙齿美白购买者”的类别,和一个“钓鱼爱好者”的类别。在投放广告的时候,使用相应组别的数据就OK。
当然,也不排除不同niche的消费者之间会有相似的特性,说什么也不如真金白银跑几组广告试试。
5 事物的两面性
总有人说Facebook广告越来越不好做了,西西莉亚希望大家还是要努力看到好的一面啊。
虽然广告越来越贵,竞争越来越激烈,可是同时机器学习的算法也越来越智能呀!
最开始的时候,Facebook的受众特征(Demoraphics)只有可怜的几个性别啊、地址什么的。看看今天,有多少个兴趣特征等着你去target!
无数的广告主在Facebook投放的广告,也在不断地帮助Facebook改进算法、筛选精准受众。这对于后入场者,也算是一种福利嘛!
再说了,西西莉亚一直以来的信念就是,做好产品更重要。好的产品是会自己说话的,广告只是帮助它把信息传达给需要的人。
所以最后正能量一波:好好做产品,好好做营销。
Keep Calm and Run The Ads!
Ending:
Facebook广告的受众推送机制是不对外公开的。
算法就像一个黑盒,你只知道你的输入(设置预算,和设置target audience),然后通过广告算法的输出(impression数/点击数/视频观看数/转化数。。。等等)来评估和调整自己的投放策略。
本文是西西莉亚结合自己的课题经验、以及搜索相关领域的论文而作出的分析。
会有一些主观的猜测和观点,主要是希望和大家一起探索这个“黑盒”内部的工作机制。
如果能给大家一些不一样的思考角度,西西莉亚也就觉得是功劳一件啦!笔芯~?
END
作者:西西莉亚 来源:西西莉亚的营销笔记
本文为作者独立观点,不代表出海笔记立场,如若转载请联系原作者。